
Basic request lifecycle with Flask goes like this:
- Flask gets a request
- is parses input parameters
- does necessary calculations
- and finally returns the result
This synchronous task is fine when a user needs the result of calculation immediately. Another use case is when the result is not relevant right now and the user just wants to schedule an execution of the task asynchronously.
Such scenarios include:
- sending an email
- creating thumbnails from uploaded images
- starting a calculation for a long CPU intensive task

Common implementation
Asynchronous tasks are usually implemented like this:
- Flask schedules a task by putting a message into some message broker (Redis, AWS SQS, RabbitMQ) upon request
- The broker is made available to the pool of possibly separate machines - workers
- Workers get messages from the broker and execute tasks
This approach has a number of advantages. Firstly, it’s sharing responsibility. Instances running Flask web server are doing only one job - serving requests. If the tasks are resource demanding Flask instances won’t suffer from high memory/CPU usage and will still serve the requests. Secondly, tasks are stored in message broker. If Flask instances die it won’t affect workers and task execution.
Nothing comes for free. This structure has more points of failure then alternatives. Libraries serving brokers have bugs. Also it may looks like a over-engineering for simple tasks.
Here are some good examples of such implementations: RQ, Celery
Alternatives
Threads
Most basic approach is to run a task in a thread. For that to work this line should be added to uwsgi configuration file:
enable-threads = true
You should run Flask with uwsg in production of course
Code for Flask application at app.py
import os
import time
from flask import Flask, jsonify
from threading import Thread
from tasks import threaded_task
app = Flask(__name__)
app.secret_key = os.urandom(42)
@app.route("/", defaults={'duration': 5})
@app.route("/<int:duration>")
def index(duration):
thread = Thread(target=threaded_task, args=(duration,))
thread.daemon = True
thread.start()
return jsonify({'thread_name': str(thread.name),
'started': True})
code for a background task doing the calculation at tasks.py
import time
def threaded_task(duration):
for i in range(duration):
print("Working... {}/{}".format(i + 1, duration))
time.sleep(1)
Demo of standard Python threads:
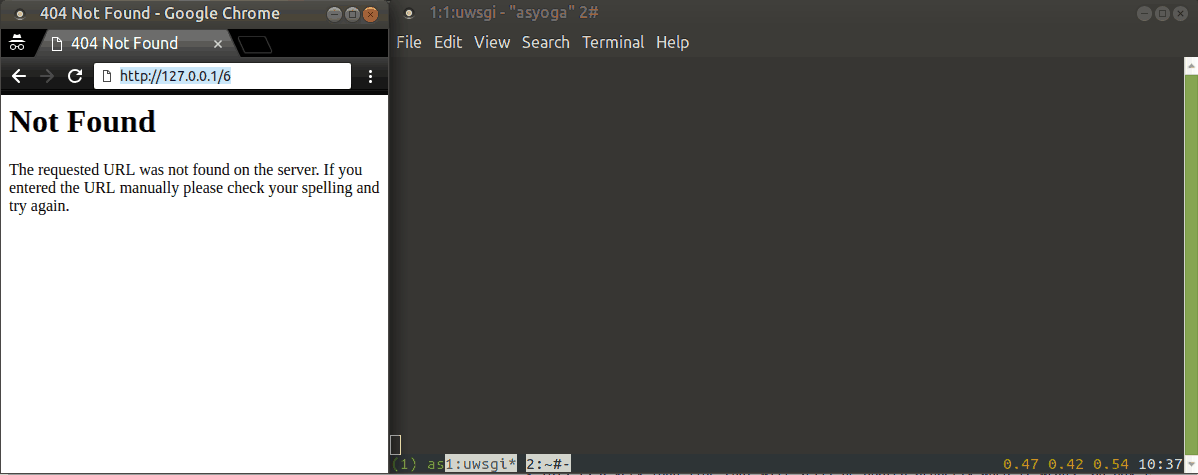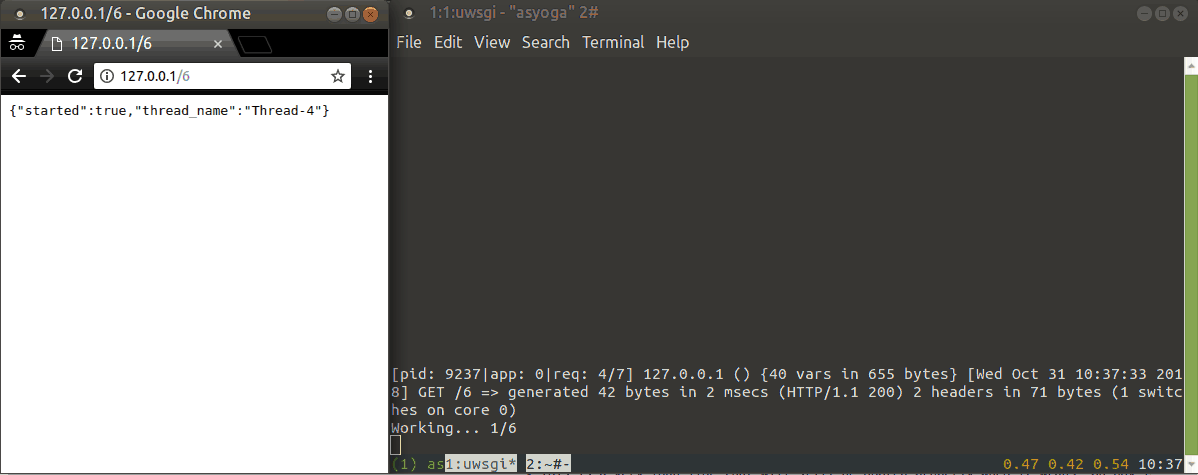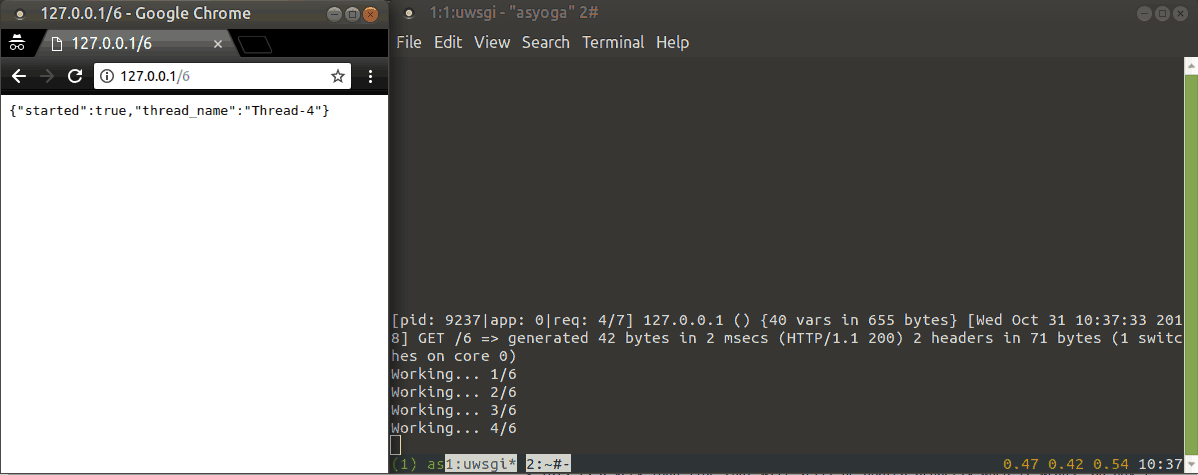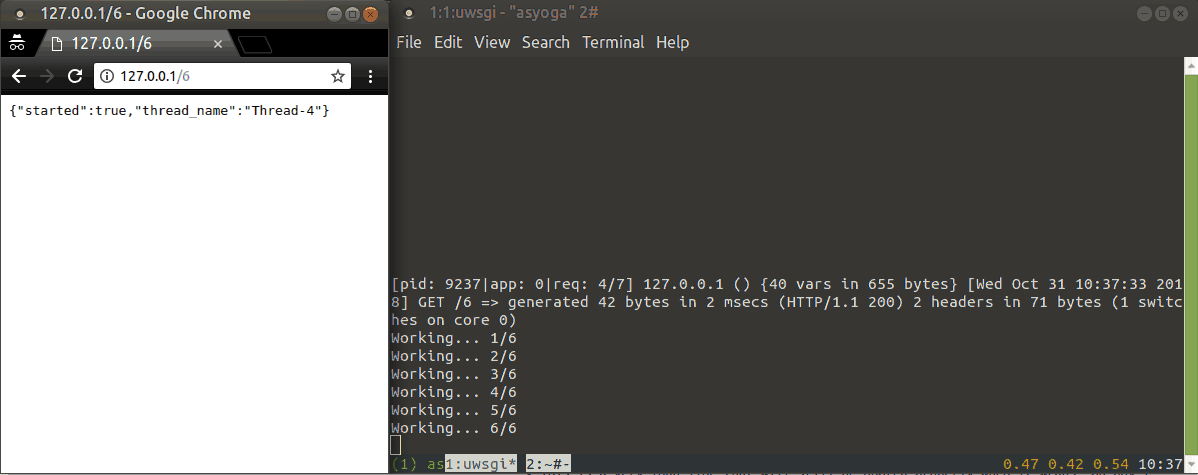
uWSGI thread
Creating and running thread may be delegated to uwsgi. So you don’t interact with threading module directly. For that there is a thread decorator available from uwsgidecorators import thread (API docs)
Code for Flask app with uwsgi threads app.py
import os
import time
from flask import Flask, jsonify
from threading import Thread
from tasks import uwsgi_task
app = Flask(__name__)
app.secret_key = os.urandom(42)
@app.route("/uwsgi_thread", defaults={'duration': 5})
@app.route("/uwsgi_thread/<int:duration>")
def uwsgi_thread(duration):
uwsgi_task(duration)
return jsonify({'started': True})
code implementing a task running in uwsgi thread tasks.py
import time
from uwsgidecorators import thread
@thread
def uwsgi_task(duration):
for i in range(duration):
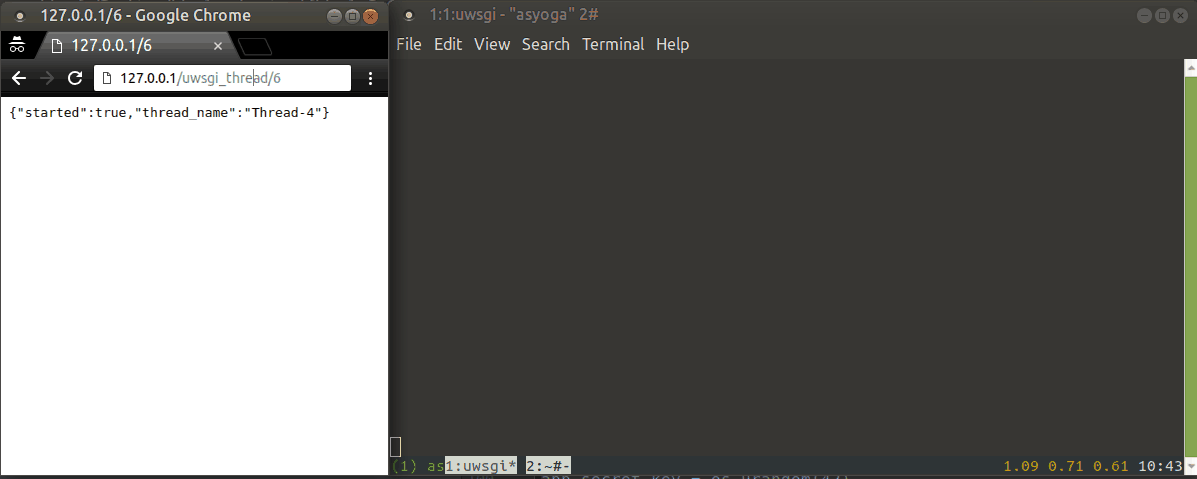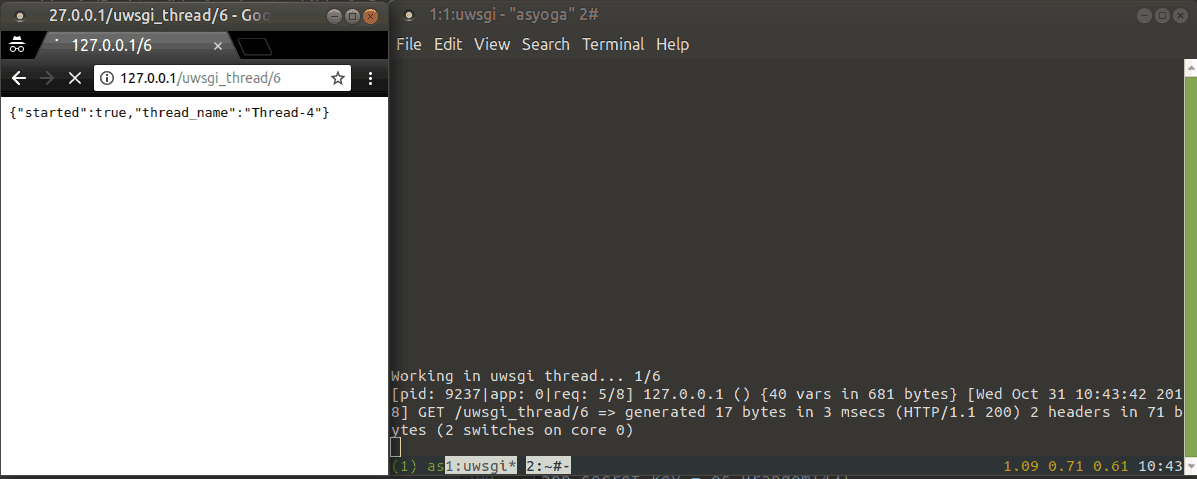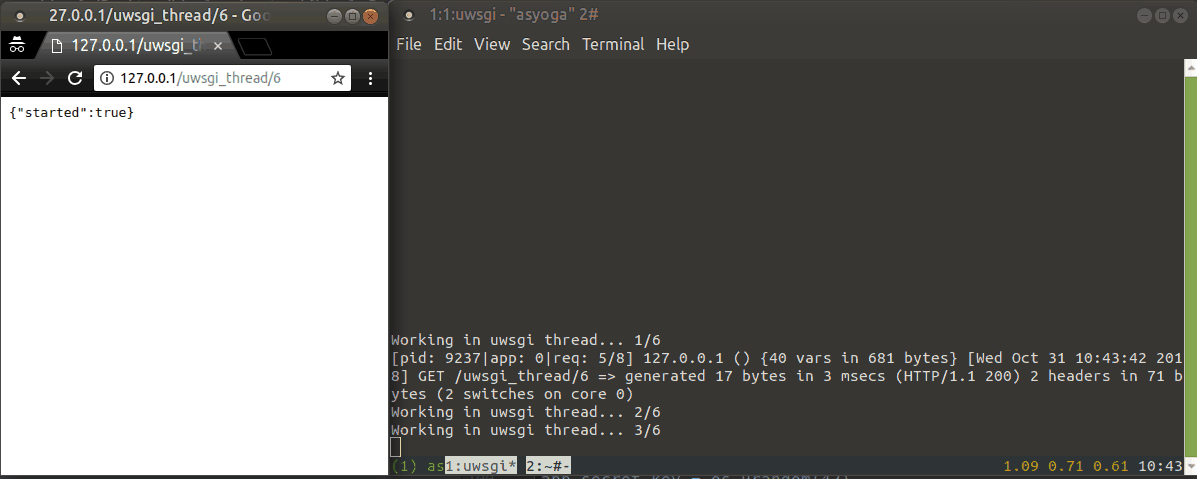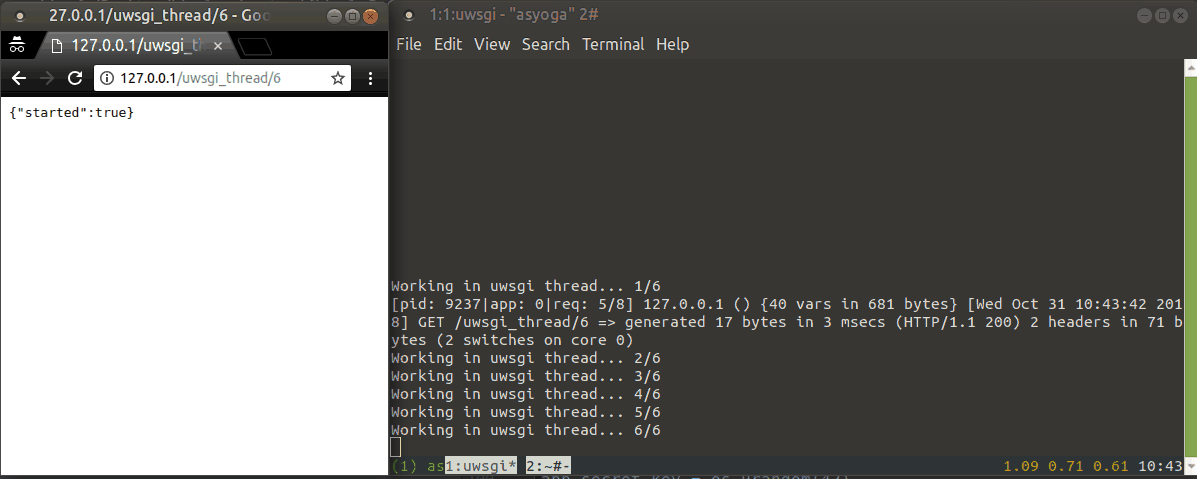
print("Working in uwsgi thread... {}/{}".format(i + 1, duration))
time.sleep(1)
Demo for uwsgi threads:
uWSGI spooler
Above examples create a thread per request and can lead to some troubles when there are many of them. To control that a task may run in a spooler with a predefined number of executors. This however requires some configuration from uwsgi side (that is uwsgi.ini)
spooler = my_spools- a path to a directory to store files representing tasks. Directory should be created beforehand.spooler-import = tasks.py- a module containing task’s code spooler workers will importspooler-frequency = 1- how ofter workers scan spool directory for tasksspooler-processes = 10- how many workers to run
After running uwsgi --ini uwsgi.ini startup log shows created processes:
spawned the uWSGI spooler on dir /home/as/Desktop/blog/my_spools with pid 10609
spawned the uWSGI spooler on dir /home/as/Desktop/blog/my_spools with pid 10610
spawned the uWSGI spooler on dir /home/as/Desktop/blog/my_spools with pid 10611
spawned the uWSGI spooler on dir /home/as/Desktop/blog/my_spools with pid 10612
spawned the uWSGI spooler on dir /home/as/Desktop/blog/my_spools with pid 10613
spawned the uWSGI spooler on dir /home/as/Desktop/blog/my_spools with pid 10614
spawned the uWSGI spooler on dir /home/as/Desktop/blog/my_spools with pid 10615
spawned the uWSGI spooler on dir /home/as/Desktop/blog/my_spools with pid 10616
spawned the uWSGI spooler on dir /home/as/Desktop/blog/my_spools with pid 10617
spawned the uWSGI spooler on dir /home/as/Desktop/blog/my_spools with pid 10618
spawned uWSGI worker 1 (pid: 10619, cores: 1)
spawned uWSGI worker 2 (pid: 10620, cores: 1)
spawned uWSGI worker 3 (pid: 10621, cores: 1)
spawned uWSGI worker 4 (pid: 10622, cores: 1)
spawned uWSGI worker 5 (pid: 10623, cores: 1)
tasks.py code is straightforward and use spool decorator from uwsgi. The task function itself should return a predefined codes though:
uwsgi.SPOOL_OKif all went welluwsgi.SPOOL_RETRYif a job need to be retried (if it’s idempotent of course)
import time
import uwsgi
from uwsgidecorators import spool
@spool
def spool_task(args):
try:
duration = int(args['duration'])
for i in range(duration):
print("Working in uwsgi spool... {}/{}".format(i + 1, duration))
time.sleep(1)
return uwsgi.SPOOL_OK
except:
return uwsgi.SPOOL_RETRY
app.py calls spool_task in the route, but I struggled a but with passing parameters. I was getting such error when passing them according to the docs:
ValueError: spooler callable dictionary must contains only bytes
So I came up with simple helper that converts keyword arguments to a dictionary with keys and values that have bytes only - prepare_spooler_args. spool decorator has a pass_arguments parameter - it may be a possible solution as well.
import os
import time
from flask import Flask, jsonify
from tasks import threaded_task, uwsgi_task, spool_task, uwsgi_tasks_task
app = Flask(__name__)
app.secret_key = os.urandom(42)
def prepare_spooler_args(**kwargs):
args = {}
for name, value in kwargs.items():
args[name.encode('utf-8')] = str(value).encode('utf-8')
return args
@app.route("/uwsgi_spool", defaults={'duration': 5})
@app.route("/uwsgi_spool/<int:duration>")
def uwsgi_spool(duration):
args = prepare_spooler_args(duration=duration)
spool_task.spool(args)
return jsonify({'started': True})
Also spool_task.spool accepts an at parameter that tell the spooler to run a task at a specified unix timestamp. To use it uwsgi_spool route code:
@app.route("/uwsgi_spool", defaults={'duration': 5})
@app.route("/uwsgi_spool/<int:duration>")
def uwsgi_spool(duration):
at = int(time.time()) + 3 # delay by 3s
args = prepare_spooler_args(duration=duration, at=at)
spool_task.spool(args)
return jsonify({'started': True})
Demo:

Wrapping up spooler
uwsgi-tasks library (pypi) wraps all the uwsgi spooler workings, especially argument passing. Also I found controlling retries as a useful feature.
Further thoughts.
uSWGI spooler is great for simple tasks. It becomes more robust with external spooler support and networking, but at that level it starts resemble a common approach with all it’s drawbacks.
The whole code is available at GitHub
Do you use background jobs with Flask? Drop me a message on linkedin